The Path to AGI
The field of natural language processing (NLP) mainly relied on recurrent neural networks (RNNs) such as LSTMs and GRUs, which processed text sequentially by passing information from one word to the next. Because each word depended on hidden states produced from previous words, these models struggled to capture long-range dependencies, making it difficult to connect information between distant parts of a sentence. Their sequential nature also prevented efficient parallelization, since words had to be processed one at a time, resulting in slow training and limited scalability on modern GPU hardware. In sequence-to-sequence tasks such as translation, these models often compressed the meaning of an entire sentence into a single fixed-length vector before decoding, creating an information bottleneck that caused important details to be lost, especially for long or complex sentences.
Breakthrough 0: Transformer
Transformers solved these limitations using self-attention, a mechanism that allows each word to directly attend to any other word in the sequence regardless of distance. Instead of relying only on sequentially propagated information, the model can immediately focus on the most relevant parts of the context, greatly improving its ability to understand long-range dependencies and relationships across text. Because all words can interact simultaneously, Transformers also removed the need for sequential processing, enabling highly parallel computation on GPUs and making training dramatically faster and more scalable.
\[\text{Attention}(Q, K, V) = \text{softmax}\left( \frac{QK^T}{\sqrt{d_k}} \right)V\]The original Transformer introduced an encoder–decoder architecture, where the encoder processes the input sequence and builds contextual representations for every token, while the decoder generates the output sequence autoregressively one token at a time. The encoder uses self-attention to build a contextual understanding of the input sequence. The decoder uses masked self-attention so each position can attend only to previously generated tokens, preserving autoregressive generation. It also uses cross-attention over the encoder outputs to condition generation on the input sequence. The key idea is separation of roles: the encoder focuses on understanding, while the decoder focuses on generation conditioned on that understanding.
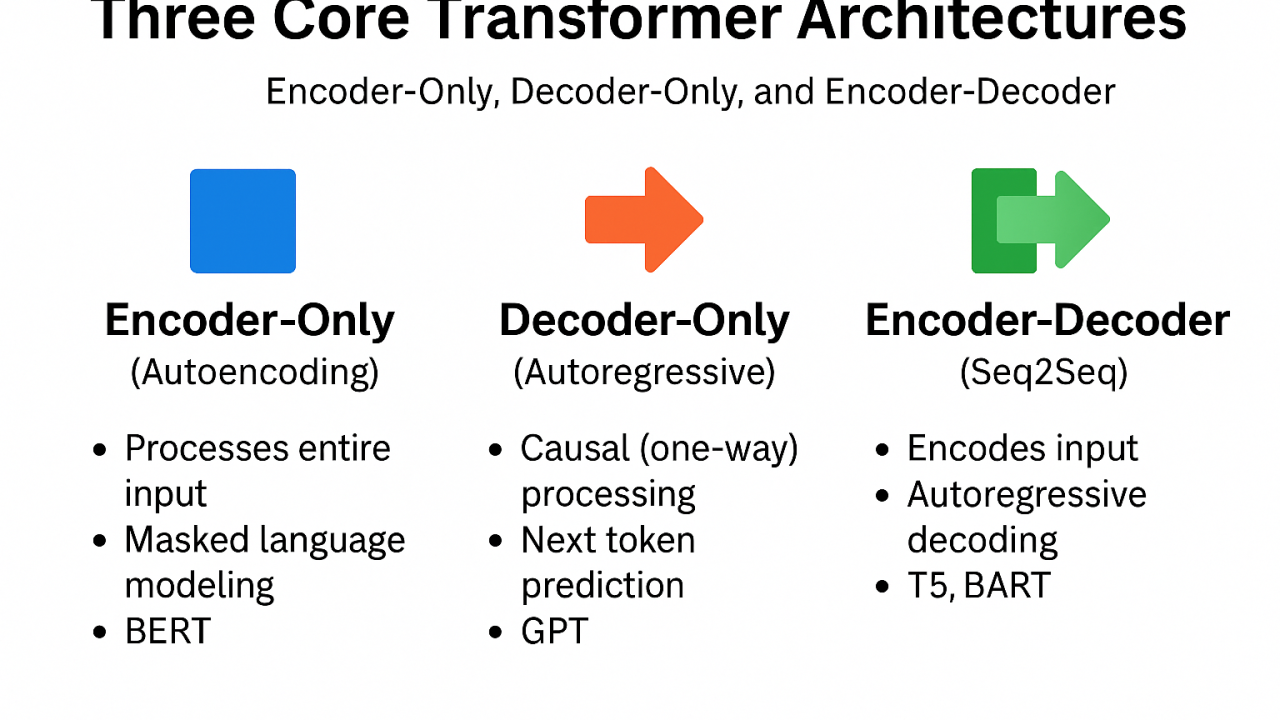
Once the Transformer architecture was introduced, researchers realized that not all tasks require both an encoder and a decoder, leading to three major variants. Encoder-only models remove the decoder and are designed primarily for language understanding tasks. Instead of generating new sequences, these models produce contextual embeddings of text, making them well suited for tasks such as semantic search and information retrieval. They can also be adapted to downstream tasks by attaching lightweight prediction heads on top of encoder representations. Common applications include sequence classification tasks such as sentiment analysis, as well as token classification or sequence labeling tasks like POS tagging and NER.
In contrast, decoder-only models remove the encoder and cross-attention components, relying solely on masked (causal) self-attention. They are trained using a next-token prediction objective, where each token is predicted based only on previously generated tokens. This autoregressive formulation makes decoder-only models highly effective for open-ended text generation and completion tasks. Finally, encoder–decoder models retain both components and are best suited for conditional generation tasks such as translation or summarization, where outputs depend heavily on a source input sequence.
Breakthrough 1: Self-supervised Pretraining + Fine-tuning (Transfer Learning)
In early NLP, models were typically trained independently for each task, requiring separate models and supervised datasets for different applications. Each model learned both language understanding and task-specific behavior simultaneously, often starting from random initialization or relying on shallow representations such as bag-of-words features or static word embeddings. This made development expensive, data-hungry, and difficult to scale across multiple tasks. The pretrain–fine-tune paradigm emerged as a fundamental shift by decoupling general language understanding from task-specific learning. Instead of training every model independently, a single model is first pretrained on large-scale unlabeled text to learn broad linguistic and semantic knowledge, then adapted to downstream tasks through lightweight fine-tuning.
This shift became especially powerful with Transformer-based models such as BERT (Bidirectional Encoder Representations from Transformers). Unlike earlier unidirectional models, BERT uses the Transformer encoder to attend to both left and right context simultaneously, enabling bidirectional language understanding. This is achieved through pretraining on two self-supervised objectives: Masked Language Modeling (MLM) and Next Sentence Prediction (NSP). In MLM, random words in a sentence are hidden and the model learns to predict them using surrounding context. NSP trains the model to predict whether one sentence follows another, helping it learn inter-sentence relationships useful for tasks such as question answering and natural language inference.
Through pretraining on massive text corpora such as Wikipedia and BooksCorpus, BERT learns transferable language representations that can be efficiently adapted to downstream tasks through fine-tuning, where only a small number of task-specific parameters, such as classification heads, are added. For sequence classification tasks, a classifier is typically added on top of the [CLS] token representation, while for sequence labeling tasks, predictions are made on top of each token. This combination led to significant performance gains across benchmarks and established transfer learning as a scalable paradigm for NLP.
Breakthrough 2: Task Unification + In Context Learning
Although the pretrain–fine-tuning paradigm makes training more efficient and scalable, it still relies on supervised datasets and separate model architectures for individual tasks. T5 (Text-to-Text Transfer Transformer) proposed unifying NLP tasks under a single text-to-text framework, where all problems are formulated as generating output text from input text and tasks are distinguished through prefixes or instructions. For example, sentiment classification becomes “sentiment: ‘I loved this movie’ → positive,” while translation becomes “translate English to German: ‘hello’ → ‘hallo’.” This removes the need for specialized architectures by using a single Transformer encoder–decoder model for many NLP tasks. However, despite this interface unification, T5 still relies on supervised fine-tuning and separate optimization for individual tasks.
GPT-style models shifted the training paradigm further by removing explicit task definitions during training. Instead of learning separate mappings for predefined tasks, models such as GPT-2 are pretrained on large-scale internet text using a next-token prediction objective. In this formulation, no task labels or task-specific datasets are required. Tasks such as translation, question answering, or summarization emerge implicitly through patterns already present in natural language text. The model therefore learns the distribution of human-written text, including instructions, explanations, and input–output patterns. During inference, users can provide examples or instructions directly in the prompt, allowing the model to infer the intended task and continue the pattern accordingly. For example, given a prompt such as “Translate English to French: ‘hello’ → ‘bonjour’, ‘good morning’ → ‘bonjour’, ‘thank you’ →”, the model can continue by producing “merci” without additional training.
This capability, known as in-context learning, is a fundamental breakthrough because it allows a single pretrained model to perform a wide variety of NLP tasks without task-specific fine-tuning or parameter updates. In-context learning emerges most naturally in autoregressive models, particularly decoder-only architectures, due to their unified sequence modeling objective. Encoder–decoder models can also support prompting behavior because they retain text generation capabilities, but they typically require more explicit multitask or instruction-style training to achieve similar task generalization. Encoder-only models are less suitable for fully general-purpose prompting because they are not designed for autoregressive text generation.
Breakthrough 3: Scaling Laws
In deep learning, scaling refers to increasing the capacity and training resources of machine learning models in order to improve performance. Scaling laws describe empirical relationships between model scale and performance, showing that larger models trained with more data and compute often achieve lower training and test loss. There are three primary dimensions of scaling: model size (number of parameters), dataset size (amount of training data), and compute budget (number of optimization steps or floating-point operations/FLOPs). Increasing model size improves representational capacity, increasing dataset size broadens the diversity of knowledge available during training, and increasing compute budget enables more effective optimization. Prior to the Transformer era, however, scaling neural networks often produced rapidly diminishing returns, where increasingly larger models and compute budgets yielded only modest performance improvements relative to the additional computational cost.
GPT-2 showed early signs of zero-shot and few-shot generalization, but its in-context learning capability remained weak and unreliable, preventing it from functioning as a truly adaptable general-purpose system. A major breakthrough came with the transition to GPT-3, where researchers observed that scaling model size, training data, and compute budget led to dramatic capability improvements without major architectural changes. GPT-3 retained essentially the same decoder-only Transformer architecture and next-token prediction objective used in GPT-2, but was trained at a much larger scale, increasing from 1.5 billion to 175 billion parameters alongside substantially larger datasets and compute budgets. Rather than exhibiting rapid diminishing returns, the larger model demonstrated strong in-context learning capabilities, allowing it to infer and perform tasks directly from examples provided in the prompt without parameter updates or task-specific fine-tuning. These results provided some of the earliest evidence that sufficiently scaled language models could function as highly adaptable systems capable of performing many NLP tasks through prompting alone.
Researchers also explored scaling encoder–decoder Transformer models such as T5 using increasingly larger model sizes, datasets, and compute budgets. While these models achieved strong performance across many supervised and instruction-based tasks, decoder-only models proved more favorable for large-scale autoregressive language modeling. In particular, decoder-only architectures demonstrated stronger emergent prompting and in-context learning behavior at scale while also benefiting from a simpler and more compute-efficient next-token prediction objective. As model scale increased, decoder-only Transformers therefore achieved stronger capability improvements per unit of compute, leading the research community to increasingly converge on scaling decoder-only architectures as the primary pathway toward general-purpose intelligence and AGI.
Breakthrough 4: Instruction tuning + RLHF
Although GPT-3 demonstrated strong language generation abilities and emerging in-context learning capability, it often behaved like a text continuation system rather than a controllable assistant. For example, it could be overly verbose, ignore explicit instructions, produce inconsistent formatting, or generate plausible but unhelpful responses when prompts were ambiguous. In many cases, small changes in prompt wording led to significantly different outputs. Both GPT-2 and GPT-3 are trained using a next-token prediction objective on large-scale internet text, which learns the statistical structure of language, world knowledge, and pattern completion abilities, but does not directly optimize models to behave as reliable assistants.
To address this limitation, instruction tuning was introduced as a first alignment step. This approach performs supervised fine-tuning (SFT) on datasets consisting of human-written instructions paired with high-quality responses. Examples include prompts such as “Explain quantum physics in simple terms,” “Write a professional email declining an offer,” or “Summarize the following paragraph,” along with corresponding ideal answers written by humans. This training teaches the model to follow natural language instructions in a consistent and structured manner. The resulting system, known as InstructGPT, can be viewed as: pretrained GPT-3 + instruction tuning.
However, instruction tuning alone is insufficient, as the model may still produce answers that are verbose, unhelpful, unsafe, or misaligned with human preferences in ambiguous situations. To address this, a second alignment step called Reinforcement Learning from Human Feedback (RLHF) is introduced. In RLHF, human annotators compare multiple model outputs for the same prompt and select which response is better. These preferences are used to train a reward model that predicts human judgment, and the language model is then optimized using reinforcement learning to maximize this learned reward. This process directly shapes the model’s behavior toward outputs that humans prefer in terms of helpfulness, clarity, and safety. The combination of instruction tuning and RLHF substantially improves model alignment and conversational reliability.
The resulting system, often referred to as ChatGPT, can be summarized as: pretrained GPT-3 + instruction tuning + RLHF. This combination transforms the model from a raw text generator into an interactive assistant capable of following complex instructions, maintaining conversational context, and producing responses aligned with human expectations. The release of ChatGPT marked a major inflection point in AI adoption, rapidly accelerating public awareness, industry deployment, and investment in large language models. It also became the fastest-growing consumer application in history, reaching 1 million users within 5 days of launch and approximately 100 million users within 2 months. In response, major technology companies rapidly launched competing systems and integrated generative AI into core products, effectively catalyzing the modern AI boom.